This article will explain presto internals and how to install presto on Azure HDInsight. If you are familiar with presto, you can jump in directly to the installation.
What is Presto?
Presto is a fast distributed SQL query engine for big data. Presto is suitable for interactive querying of petabytes of data.
Presto Architecture
To understand how presto works, lets look at the presto architecture. The following figure from the presto documentation highlights key components of presto.
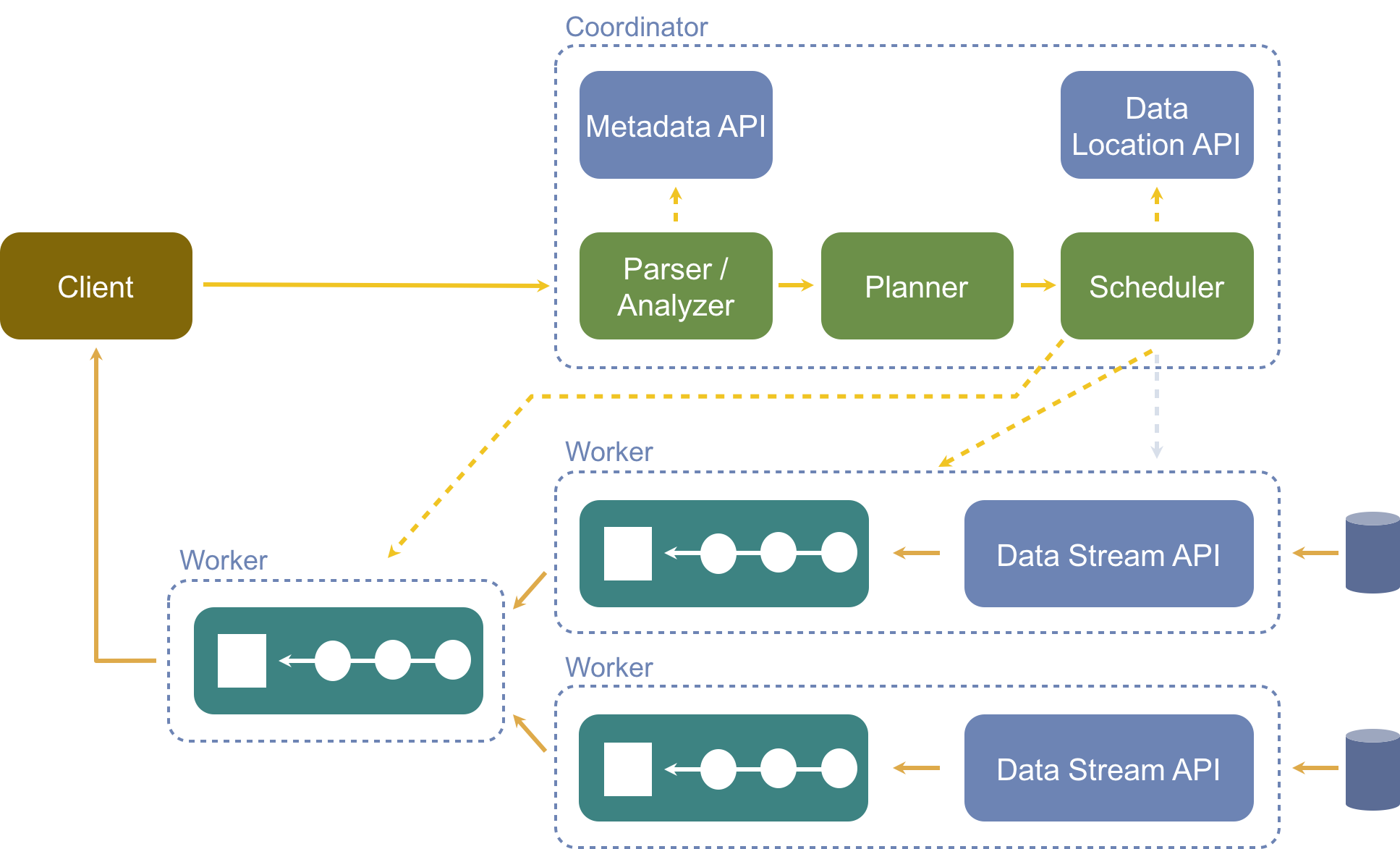
Clients
Clients are where you submit queries to Presto. Clients can use JDBC/ODBC/REST protocol to talk to coordinator.
Coordinator
Presto coordinator is responsible for managing workernode membership, parsing the queries, generating execution plan and managing execution of the query. During the execution of the queries, it also manages the delivery of the data between tasks.
The coordinator translates the given query into logical plan. The logical plan is composed of series of stages and each stage is then executed in a distributed fashion using several tasks across workers. This is very similar to other distributed query execution engines like Hive and Spark.
Workers
Presto worker is responsible for executing tasks and processing data. This is where the real work of processing the data happens.
Communication
Each presto worker advertises itself to the coordinator through discovery server. All the communication in presto between Coordinator, workers and clients happen via REST API.
Connectors
Presto has a federated query model where each data sources is a presto connector. One way to think about different presto connectors is similar to how different drivers enable a database to talk to multiple sources. Some of the currently available connectors on the presto project:
Catalog
Each catalog in presto is associated with a specific connector, specified in the catalog configuration with connector.name. Based on this name Presto (Catalog Manager) decides how to query a particular data source. When writing a query in Presto, you can use the fully-qualified name that contains connector.schemaname.tablename. For example, if you have a hive table revenue in database name prod, you can refer it as hive.prod.revenue. The below figure highlights how multiple catalogs fit in presto:
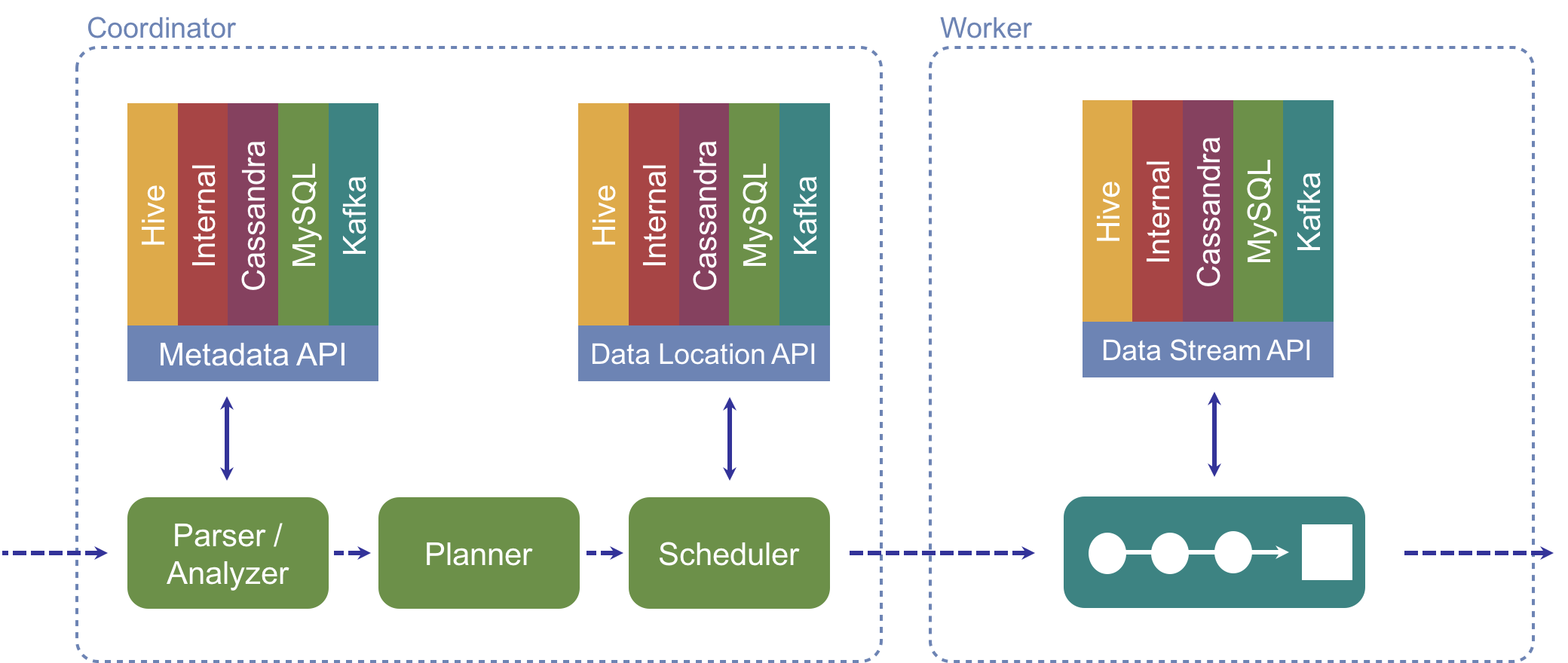
As showed in the figure, each connector implements two APIs
- Data streaming API : Specifies how to read/write the data.
- Metadata API : Specifies what is the schema or how to interpret the data.
For further information about presto, presto documentation and presto user group are great places to look :)
Presto Use Cases
An obvious use case for Presto is for traditional data analysis similar to SQL-on-Hadoop and Spark-SQL. Like other engines, Presto support both SQL and UDFs. Presto supports wide range of inbuilt and user defined functions. The SQL syntax is similar to Hive and Spark SQL syntax and should make you feel home. Presto even has a migration guide from Hive. :) Presto JDBC/ODBC drivers allow you to connect to wide range of tools like Tableu easily. Presto is also well suited for powering analytics dashboards and has client libraries in your favorite language, if you prefer to talk programmatically. And while we are at it, the auto-complete in presto CLI is pretty dope! Oh and did I mention how cool (and detailed) the presto UI is ?
Presto is very successfully used by number of organizations for their fast data analysis needs and in using large scale SQL analytics. One of the prime aspect of Presto that caught my attention, however, was the ability to query various data sources in a single query. This is so magical ✨, let me give you an example to illustrate it,
SELECT s.region,
revenue
FROM hive.weblog.clickstreams s
JOIN mysql.prod.transections t
ON s.userid = t.userid
GROUP BY s.region
ORDER BY revenue DESC
LIMIT 100The above query joins data in Hive WASB with data in a MySQL database. This obviates the need to bring and manage all the data under a single system . This allows best tool for the job, while still retaining ability to query them. In the example above, the transaction data resided in the SQL database while clickstream logs are in Hive/WASB and the above query joins them to find out top 100 regions by revenue.
This solves a big pain point of big data, where right now you have to copy them in to single location and manage it under a single system. The big data, IMO, should be about deriving insights from data and not managing ETL pipelines and dealing with deduplication issues. Each system has different tradeoffs and are fit to and serve only part of the larger picture in the big data architectures. This, in my opinion, is so important since, the world where each system wants to be the only system to store and process data, presto acknowledges the need to be a good citizen in the big data architecture.
Who is using Presto?
Presto started out at Facebook and has become key piece in the data infrastructure of many organizations. Some of the prominent names who use presto are:
- Netflix
- Airbnb
- Dropbox
- Uber
- NASDAQ
- Walmart
- Alibaba
- … many more and YOU by following the next secion :)
Installing Presto on HDInsight
Now that we know how Presto works, lets get our hand dirty. HDInsight Custom action scripts allows extending HDInsight in arbitrary ways through a bash script. Presto custom action script can be used on new and existing 3.5+ HDInsight hadoop clusters to install and run presto. Creating a presto cluster is very simple : run script action with following URL on headnodes and workernodes.
https://raw.githubusercontent.com/dharmeshkakadia/presto-hdinsight/master/installpresto.sh
The below GIF shows the steps while creating a cluster and specifying the presto script.
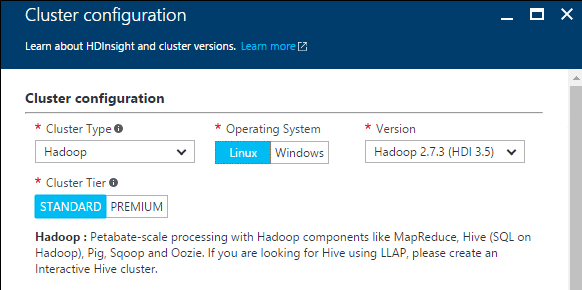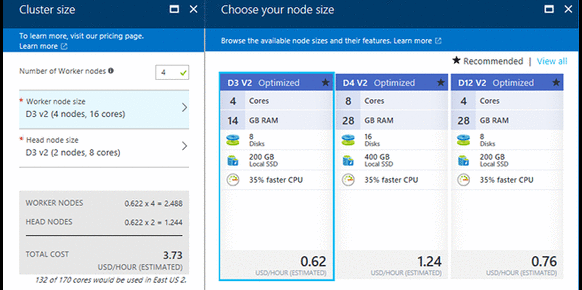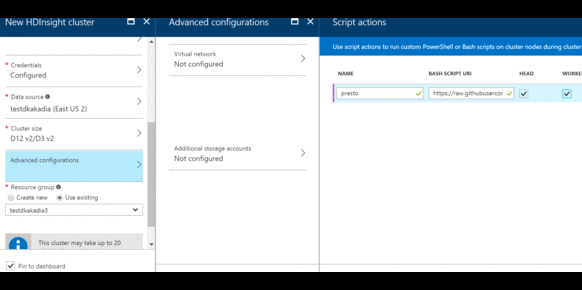
Now you can SSH to the cluster and start using presto.
presto --schema defaultThis will drop you into presto-cli and you can start analyzing data right away.
presto> select count(*) from hivesampletable;By Default, Hive and TPCH connectors are configured. Hive connector is configured to use the default installed Hive installation, so all the tables from Hive will be automatically visible in presto. You can also play around with TPCH or TPCDS datasets.
Inner working of installation script
If you are interested in details of what is the above script action is doing, let me break it down. We use Apache Slider to manage presto resources through YARN. In a N node standalone cluster with the script will create 1 presto co-ordinator, N-2 presto worker containers with maximum memory, 1 slider AM that monitors containers and relaunches them on failures.
Customer action invokes installpresto.sh, which performs following steps:
- Download the github repo.
- Create a presto build that has support of Windows Azure Storage Blob (WASB). Note that this step is required since the WASB support has not merged in the upstream Presto yet. The script builds the package under
/var/lib/presto/on the primary headnode. - Install the created slider package.
- Create appropriate presto-slider configuration files (
/var/lib/presto/presto-hdinsight-master/appConfig-default.jsonand/var/lib/presto/presto-hdinsight-master/resources-default.json) for the presto slider package. All the configs are generated by createconfigs.sh script. - Start the presto with slider.
- Wait for the presto to come up and install preso-cli in the
/usr/local/bin/.
You can customize the presto installation to suit your needs.
Airpal
Airpal is the web query interface for presto. The following GIF from the airpal website gives a good overview of available features in airpal.
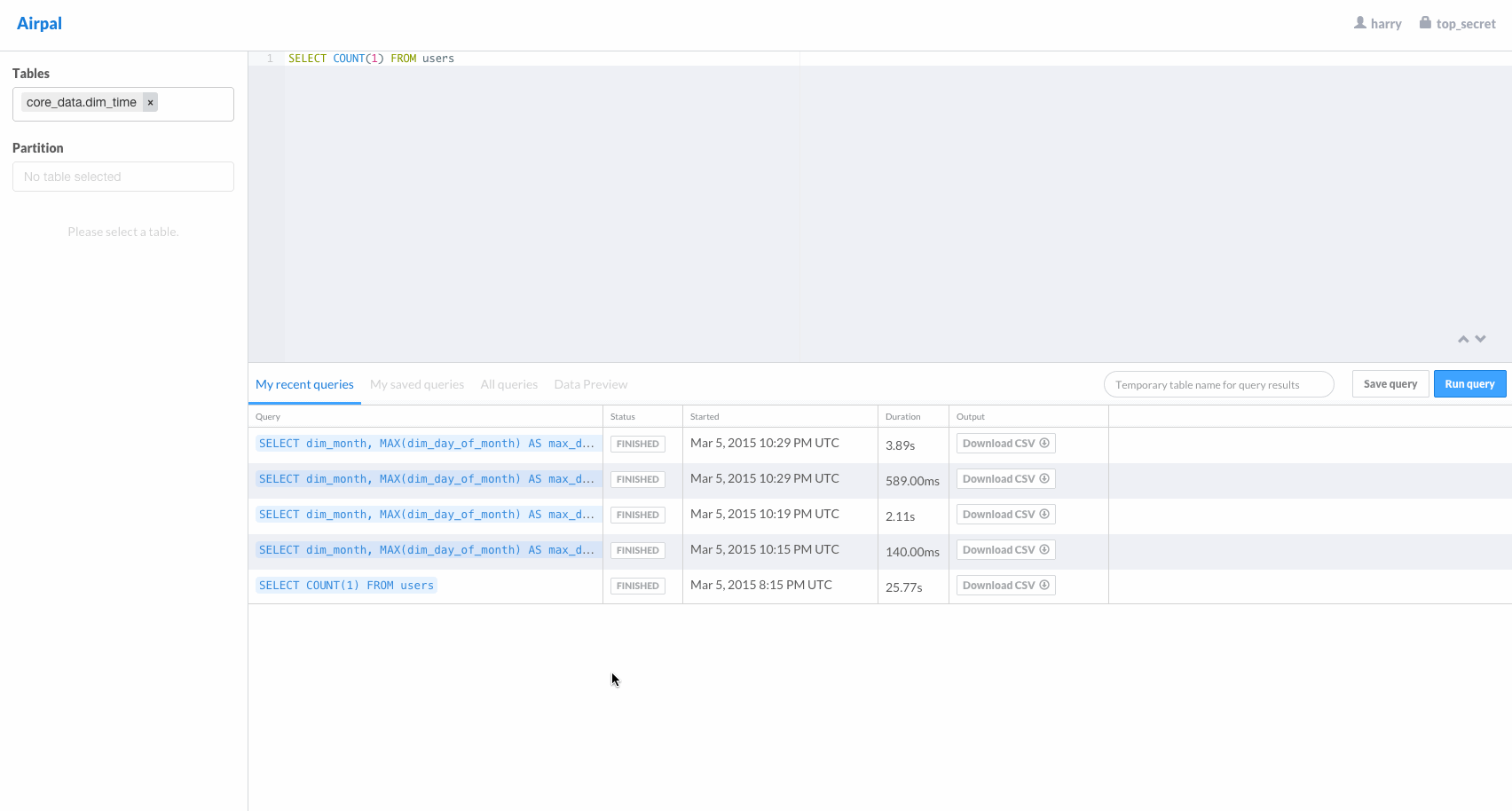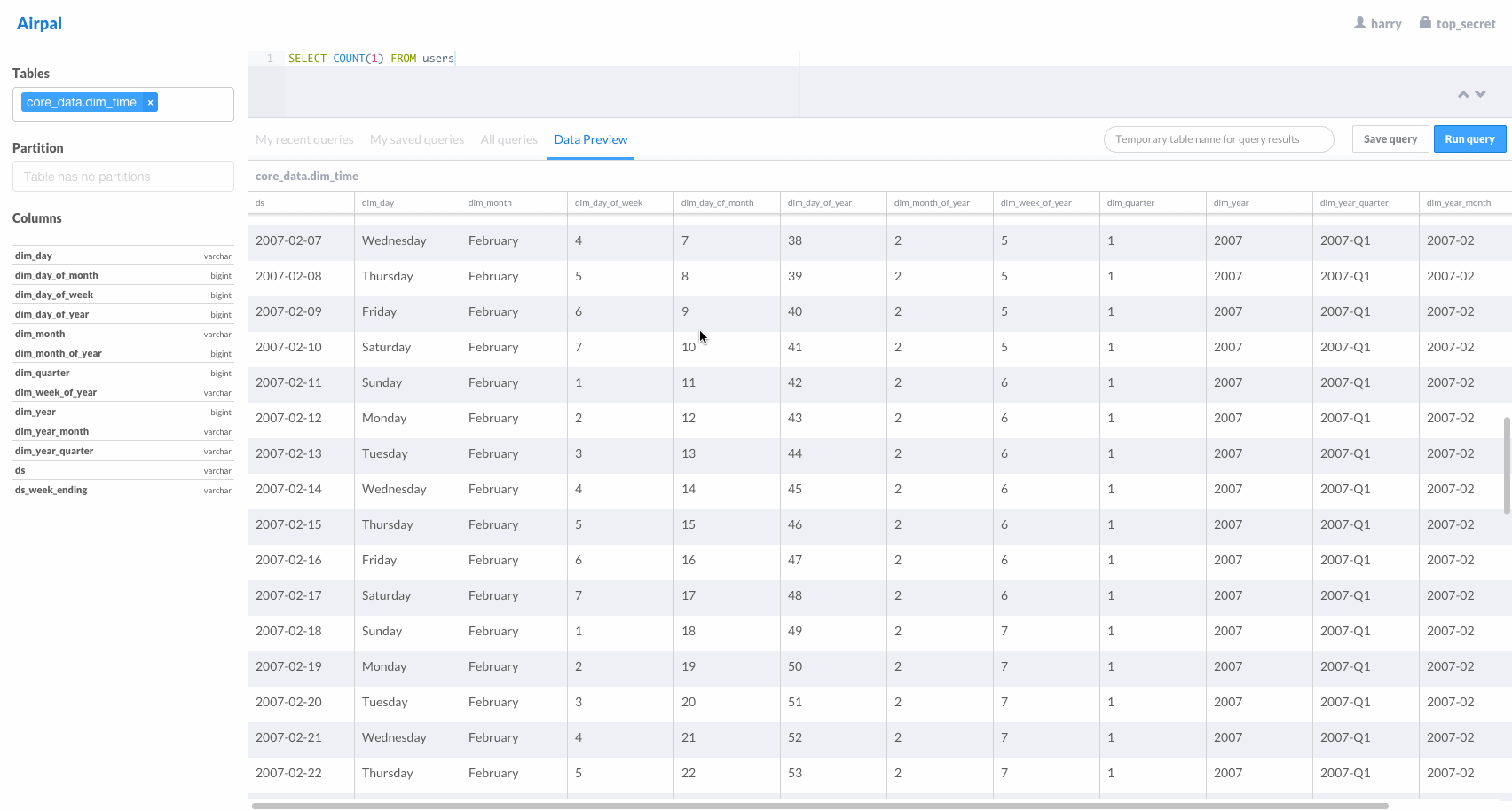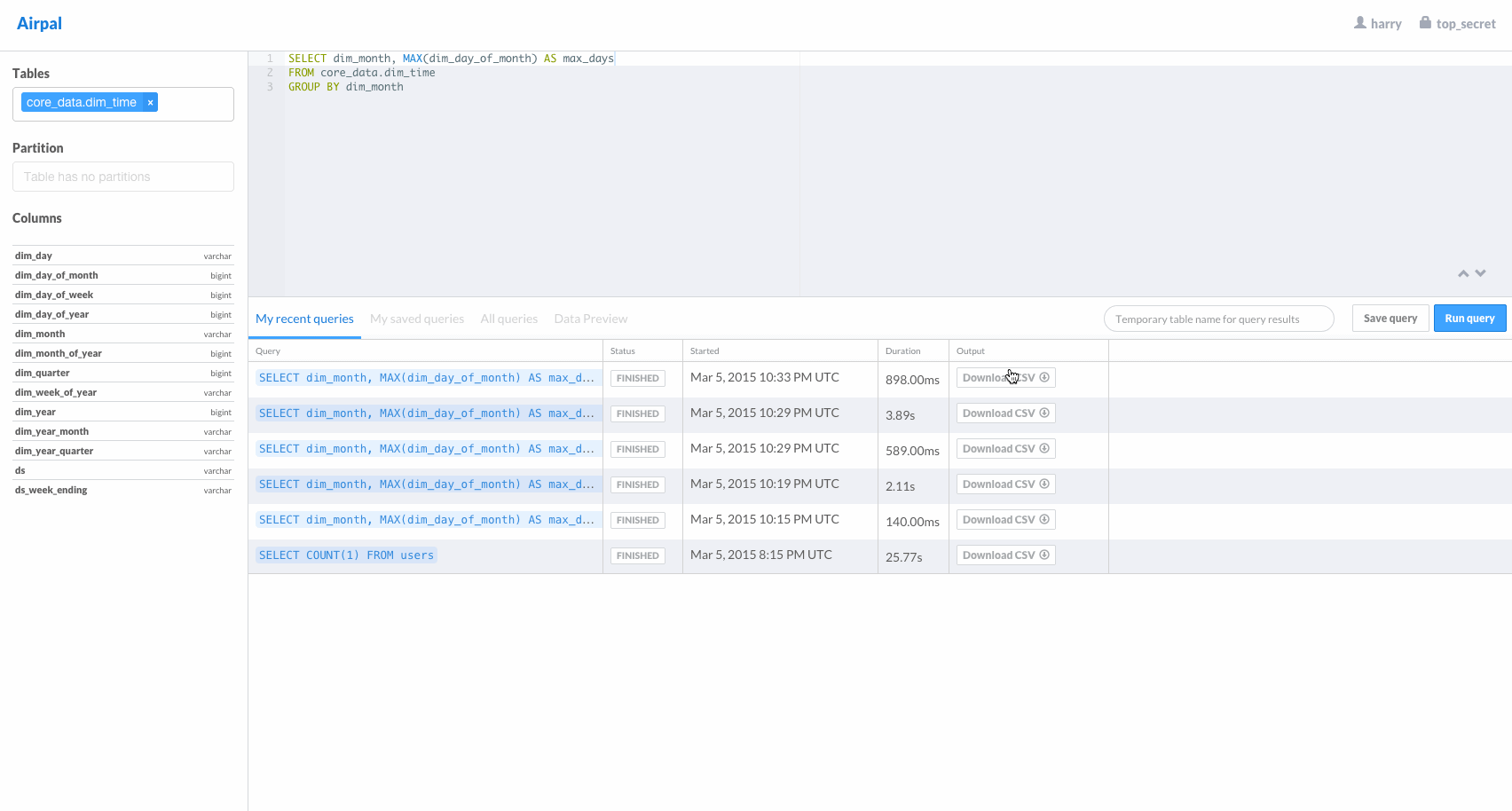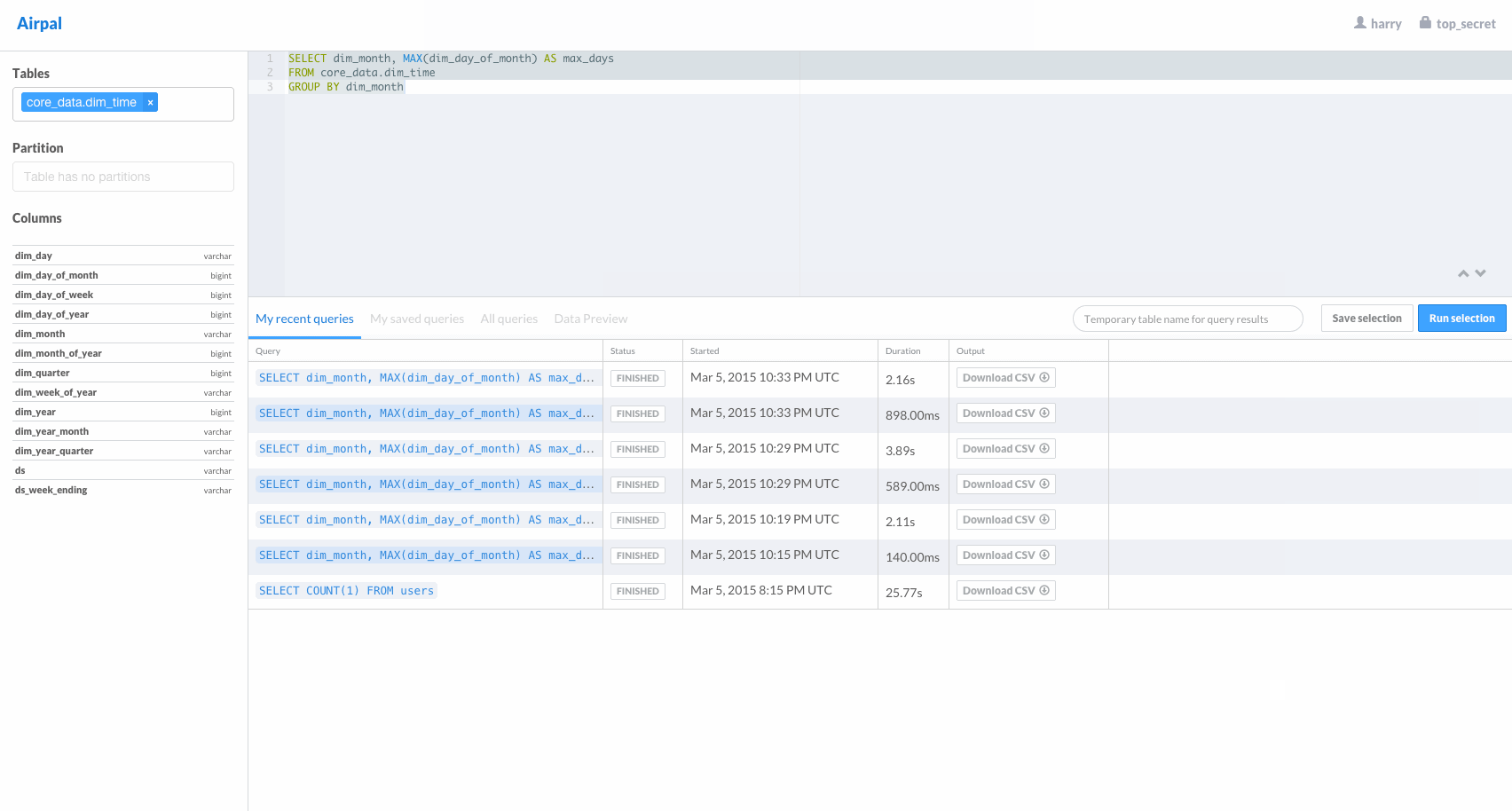
Installing Airpal on headnode
You can install Airpal on the cluster headnode using following the steps.
- Install presto as shown in the previous section.
- Now, SSH to the headnode and run the following command to know address of the presto coordinator
sudo slider registry --name presto1 --getexp prestoYou will see output like following, note the IP:Port.
{
"coordinator_address" : [ {
"value" : "10.0.0.11:9090",
"level" : "application",
"updatedTime" : "Sat Feb 25 05:45:14 UTC 2017"
}- Run the install airpal script as sudo as follows with the address noted from the previous step.
cd /var/lib/presto/
sudo ./presto-hdinsight-master/installpresto.sh 10.0.0.11:9090This script installs airpal with all its dependencies. Once the script is complete, airpal will be running on port 9191. Note that, to use airpal from your browser, you have to setup local tunneling and SOCKS proxy on your browser. Or you can install airpal on edgenode.
Installing Airpal on Edgenode
HDInsight Edgenodes are acceisble to/from outside world and you can install any software on them. You can deploy Airpal on HDInsight Edge node using as follows:
- Install presto using the above steps.
- Now, SSH to the headnode and run the following command to figure out address of the presto coordinator
sudo slider registry --name presto1 --getexp prestoYou will see output like following, note the IP:Port.
{
"coordinator_address" : [ {
"value" : "10.0.0.11:9090",
"level" : "application",
"updatedTime" : "Sat Feb 25 05:45:14 UTC 2017"
}Click here to create an edgenode and deploy airpal.
Provide Clustername, EdgeNodeSize and PrestoAddress (noted above).
To access airpal UI, go to your cluster on azure portal and navigate to Applications and click on portal. You have to login with cluster login credentials.
Conclusion
Now, that you have Presto and Airpal running on HDInsight, go do your data analysis. If you find any issues, feel free to report them. Note that, like all other custom action scripts, this is not a Microsoft Supported product.
