In this post we will try to demystify details about Spark Parser and how we can implement a very simple language with the use of same parser toolkit that Spark uses.
Intro
Apache Spark is a widely used analytics and machine learning engine, which you have probably heard of. You can use Spark with various languages - Scala, Java, Python - to perform a wide variety of tasks - streaming, ETL, SQL, ML or graph computations. Spark SQL/dataframe is one of the most popular ways to interact with Spark. Spark SQL provides SQL syntax and SQL like API to build complex computation graphs. Spark SQL relies on a common compiler framework to translate the high level SQL code into executable low level code. Spark Catalyst is the name of that compiler framework.
Catalyst Architecture
Following image describes various steps and components of Spark Catalyst. The image is taken from databricks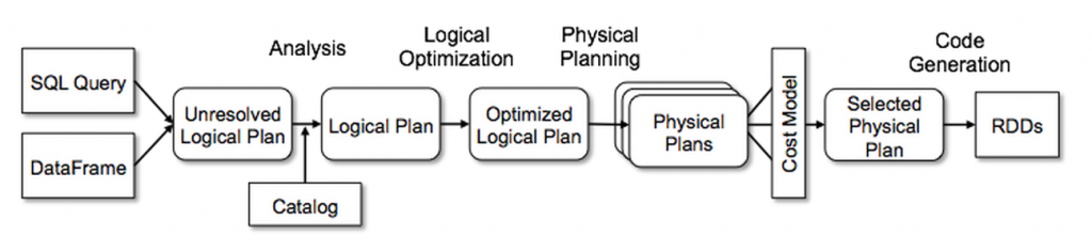
Like any compiler, Spark Catalyst compiler has a various modules for different phases of compilation process. In this post we will focus more on parser part of the Catalyst and will also write an example program that parses simple string into well defined tokens.
Grammar and parsers
Grammar + Parser helps in answering the following question:
Is given statement complaint to the rules of the language?
For example, is select * from sample a valid Spark statement or not?
Why understand parser
- Understand will (or why is) the given statement giving error on parsing?
- Is this a keyword in Spark or not?
- Add new feature (say merge statement support)
- Build new tools, say our own editor for Spark…
- Generating automated tests from the grammar
Spark grammar
Spark grammar is LL. Spark parser first tries to parse it using SLL mode (Strong LL), which is faster. If that fails, it will try to parse it as LL. LL stands for Left to right parsing, deriving leftmost derivation.
A grammar G = ( N, T, P, S ) is said to be strong LL(k) for some fixed natural number k if for all nonterminals A, and for any two distinct A-productions in the grammar.
The strong LL(k) grammars are a subset of the LL(k) grammars that can be parsed without knowledge of the left-context of the parse. That is, each parsing decision is based only on the next k tokens of the input for the current nonterminal that is being expanded. Or in other words, parsers that ignore the parser call stack for prediction are called Strong LL (SLL) parsers.
ANTLR
ANTLR stands for ANother Tool for Language Recognition. Its a toolkit for building languages and parsers. ANTLR can be used as a parser generator for reading, processing, executing, or translating structured text. ANTLR generates a parser that can build and walk parse trees. Its used widely by many big data languages (Groovy, Cassandra, Hive, …)
ANTLR operators
ANTLR has following operators that we can use to define structure of any language.
| alternatives
. any character
? repeated zero or one time
+ repeated one or more times
* repeated zero or more timesSimple ANTLR end to end example
Now we will build a very simple end-to-end example, that recognizes any string starting with Hello and extracts the alphabetic word following Hello. So, for string Hello World it would extract World, string Hello Dharmesh it would identify Dharmesh and so on.
First we need to define our grammer formally. Following is the formal definition of our grammer called Hello, where we define word we want to extract as ID with [a-z]+ which means any character([a-z]) 1 or more time(+). We also define whitespace as WS and finally define the msg as string 'Hello' followed by ID:
grammar Hello;
msg : 'Hello' ID;
ID : [a-z]+ ;
WS : [ \t\r\n]+ -> skip ;Now, we have to implement Visiter interface to decide what to do when we encounter/parse/traverse a node in the grammar. For our simple example, we are just going to print the ID value as the parser enters and exits the node while parsing the input string.
public class HelloVister extends HelloBaseListener {
public void enterMsg(HelloParser.MsgContext ctx){
System.out.println("Entering Msg : " + ctx.ID().getText());
}
public void exitMsg(HelloParser.MsgContext ctx){
System.out.println("Exiting Msg");
}
}Finally, we have to initialize the lexer, parser etc. and start the parsing in our main program after passing the string Hello World.
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
public class Hello {
public static void main(String[] args) {
HelloLexer lexer = new HelloLexer(new ANTLRInputStream("Hello world"));
HelloParser parser = new HelloParser(new CommonTokenStream(lexer));
ParseTreeWalker visiter = new ParseTreeWalker();
visiter.walk(new HelloVister(),parser.msg());
}
}
Our example code uses ANTLR maven plugin, which takes care of generating the code for the grammar.
To compile the project and generate parser code,
mvn compileTo run the program that passes in Hello World to our parser,
mvn exec:java -qwhich would print
Entering Msg : world
Exiting MsgThats it!
P.S. This post is made from the the notebook that I used at for our internal Microsoft presentation and had been sitting in my TODO for quite some time, but was not published here on blog. The Corona virus lockdown has allowed me to finally get to this. Stay safe everyone !!
