Hive Hooks are little known gems that can be used for many purposes. In this post we will take a deeper look at what a Hive hook is and how to write and use a Hive hook (along with the full source code!).
What is Hive?
For the readers new to Hive, it provides an SQL interface to Hadoop. Hive can be thought of as a compiler that translates SQL (strictly speaking Hive Query Language - HQL, a variant of SQL) into a set of Mapreduce/Tez/Spark jobs. Thus, Hive is very instrumental in enabling non programmers to use Hadoop infrastructure. Traditionally, Hive had only one backend, namely MapReduce. But with recent versions, Hive supports Spark and Tez also as execution engines. This makes Hive a great tool for exploratory data analysis.
The following diagram and terms from the Hive documentation explains high level design of Hive with MapReduce backend.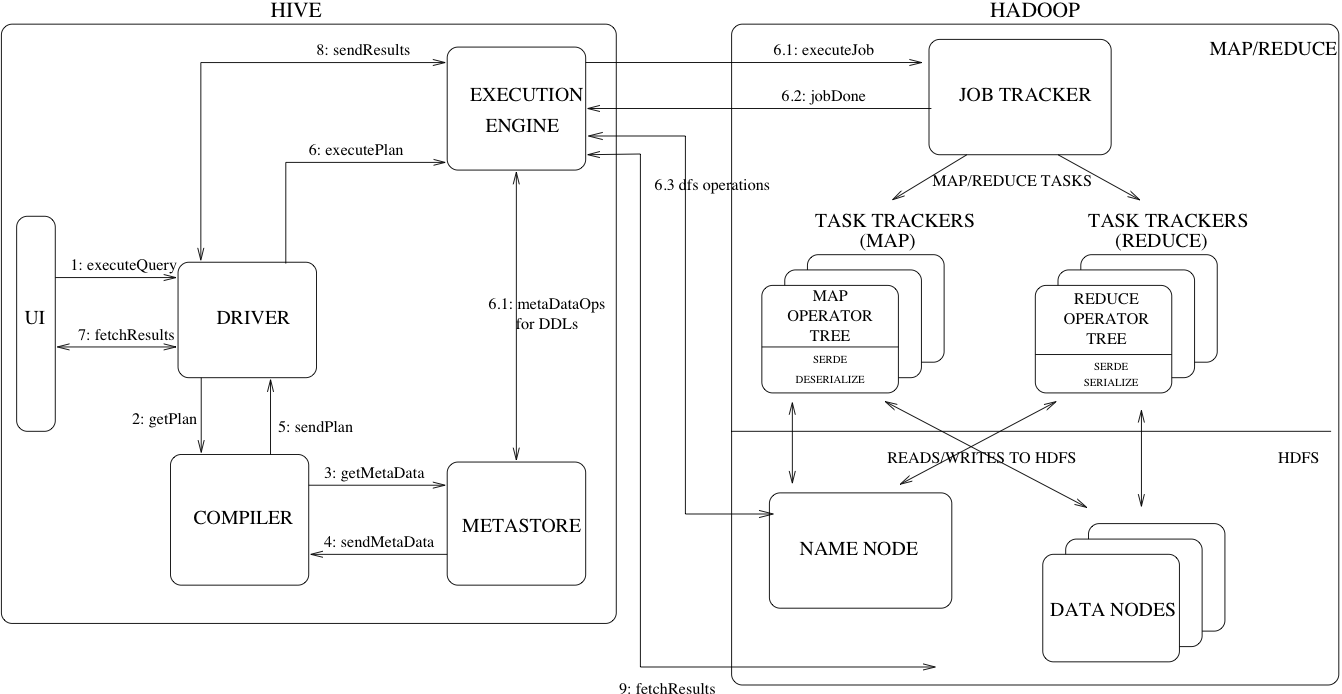
- Driver – The component which receives the queries. This component implements the notion of session handles and provides execute and fetch APIs modeled on JDBC/ODBC interfaces.
- Compiler – The component that parses the query, does semantic analysis on the different query blocks and query expressions and eventually generates an execution plan with the help of the table and partition metadata looked up from the metastore.
- Metastore – The component that stores all the structure information of the various tables and partitions in the warehouse including column and column type information, the serializers and deserializers necessary to read and write data and the corresponding HDFS files where the data is stored.
- Execution Engine – The component which executes the execution plan created by the compiler. The plan is a DAG of stages. The execution engine manages the dependencies between these different stages of the plan and executes these stages on the appropriate system components.
What is a Hive Hook?
In general, Hook is a mechanism for intercepting events, messages or function calls during processing. Hive hooks are mechanism to tie into the internal working of Hive without the need of recompiling Hive. Hooks in this sense provide ability to extend and integrate external functionality with Hive. In other words Hive hooks can be used to run/inject some code during various steps of query processing. Depending on the type of hook it can be invoked at different point during query processing:
- Pre-execution hooks are invoked before the execution of the query by the execution engine begins. Note that at this point you have Hive already has an optimized query plan for the execution ready.
- Post-execution hooks are invoked after the execution of the query is finished and before the results are returned to the user.
- Failure-execution hooks are invoked when the execution of the query fails.
- Pre-driver-run and post-driver-run hooks are invoked before and after the driver is run on the query.
- Pre-semantic-analyzer and Post-semantic-analyzer hooks are invoked before and after Hive runs semantic analyzer on the query string.
Life of a Hive Query
At a high level here are the steps that happen during the processing of a given query in Hive. Don’t worry if you are not familiar with some of these terms, we will discuss them later.
Driver.run()takes the commandorg.apache.hadoop.hive.ql.HiveDriverRunHook.preDriverRun()which readshive.exec.pre.hooksconfiguration to decide which are the pre-hooks that needs to be run.org.apache.hadoop.hive.ql.Driver.compile()starts processing the query by creating the abstract syntax tree (AST) representing the query.org.apache.hadoop.hive.ql.parse.AbstractSemanticAnalyzerHook(which implementsHiveSemanticAnalyzerHook) callspreAnalyze()method.- Semantic analysis is performed on the AST.
org.apache.hadoop.hive.ql.parse.AbstractSemanticAnalyzerHook.postAnalyze()is called which executes all the configured Semantic Analyzer Hooks.- Create and validate the physical query plan.
Driver.execute()is ready to run the jobs.org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext.run()is called to execute all the pre-execution hooks.org.apache.hadoop.hive.ql.hooks.ExecDriver.execute()runs all the jobs of the query.- For each job
org.apache.hadoop.hive.ql.stats.ClientStatsPublisher.run()is called to publish statistics for the job. The interval is controlled byhive.exec.counters.pull.intervalconfiguration - the default is 1000ms. The publishers to be called is decided by readinghive.client.stats.publishersconfiguration. You can also specify what counters to be published by settinghive.client.stats.counters. - Finish all the tasks.
- (optional) If a task fails, call hooks configured with
hive.exec.failure.hooks. - Run post execution hooks by calling
ExecuteWithHookContext.run()on hooks specified inhive.exec.post.hooks. - Run
org.apache.hadoop.hive.ql.HiveDriverRunHook.postDriverRun()controlled byhive.exec.driver.run.hooks. Note that this is run after the query finishes running and before returning the results to the client. - Return the result.
Hive Hook API
There are many different kinds of Hooks that Hive supports. Hook interface is the parent of all the Hooks in Hive. It is an empty interface and has been extended by following interfaces for specific hooks:
- PreExecute and PostExecute extends Hook interface to Pre and Post execution hooks.
- ExecuteWithHookContext extends the Hook interface to pass on the HookContext to the hooks. HookContext wraps all the information that can be used by hooks. The HookContext is passed to all the hooks that have “WithContext” in the name.
- HiveDriverRunHook extends Hook interface to run during driver phases which allows custom logic processing commands in Hive.
- HiveSemanticAnalyzerHook extends the Hook interface to allows plugging in custom logic for semantic analysis of the query. It has
preAnalyze()andpostAnalyze()methods that are executed before and after Hive performs its own semantic analysis. - HiveSessionHook extends Hook interface to provide session level hooks. The hook is called when a new session is started. It is configured with
hive.server2.session.hook. - Hive 1.1 added Query Redactor Hooks. It is an abstract class that implements Hook interface that is useful for removing sensitive information about the query before putting it into job.xml. This hooks can be configured by setting
hive.exec.query.redactor.hooksproperty.
Hive codebase have some hook examples. Right now it has following hook implementations:
- DriverTestHook is a very simple HiveDriverRunHook that prints the command that you used to the output.
- PreExecutePrinter and PostExecutePrinter are examples of pre and post execution hooks that prints the parameters to the output.
- ATSHook is a ExecuteWithHookContext that pushes query and plan information to YARN timeline server
- EnforceReadOnlyTables is a ExecuteWithHookContext that prevents modification of read-only tables.
- LineageLogger is a ExecuteWithHookContext which logs the lineage information of the query into the log file. LineageInfo contains all the information about wuery lineage.
- PostExecOrcFileDump is a post-execution hook that prints ORC file information.
- PostExecTezSummaryPrinter is a post-execution hook that prints a summary of Tez counters.
- UpdateInputAccessTimeHook is a pre-execution hook that updates the access time of all the input tables before running the query.
Writing Hive Hook
We will now write an example Hive hook and setup it with Hive. We will write a simple pre-execution hook that will write “Hello from the hook !!”. The source code of the example is available on github.
- lets setup a project using maven. Create a pom.xml in your project directory.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hive-hook-example</groupId>
<artifactId>Hive-hook-example</artifactId>
<version>1.0</version>
</project>- Now add the
hive-execpackage as a dependency to your project by adding the following into your pom file.
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>- Now lets create a class that implements the hook interface. We will call our class HiveExampleHook which will implement the
org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext. This interface has only one method with following signature,
public void run(HookContext) throws Exception;For now we will just put a single statement
System.out.println("Hello from the hook !!");So, the complete class looks as follows:
import org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext;
import org.apache.hadoop.hive.ql.hooks.HookContext;
public class HiveExampleHook implements ExecuteWithHookContext {
public void run(HookContext hookContext) throws Exception {
System.out.println("Hello from the hook !!");
}
}- Compile and package our hook code into a jar by issuing the following command:
mvn packageThis should generate a file named Hive-hook-example-1.0.jar in the target directory.
- Now add the generated jar into the Hive classpath and set it as pre-execution hook. Start the Hive terminal and issue the following commands. Note that you have to
add jar target/Hive-hook-example-1.0.jar;
set hive.exec.pre.hooks=HiveExampleHook;That’s all. We are now all set to see “Hello from hook !!” before all the Hive statements. You can check is by issuing show tables;. Note that the step 5 needs to be done for every Hive session (every time you start a new Hive terminal). You can make it permanent by setting the property in the hive-site.xml file.
If you want to see another simple Hive hook with a real use case you can check out my YarnReservationHook. It uses Yarn’s reservation API to reserve resources for given query just before the query starts the execution via a pre-execution- hook. We have another simple post-execution-hook that cleans up the reservation at the end of query.
Metastore Hooks
Hive also has metastore specific hooks for intercepting metastore events. HiveMetaHook represent the root of metastore hooks.
Metastore initialization hooks are invoked when Hive metastore is initialized. If we want to log what new tables/databases are created in Hive to external services, then Metastore hooks are the place to do it. This can be used for example to keep HBase in sync with Hive metastore. HiveMetaHook interface defines the following methods that are invoked as part of metastore transactions.
public void preCreateTable(Table table) throws MetaException;
public void rollbackCreateTable(Table table) throws MetaException;
public void commitCreateTable(Table table) throws MetaException;
public void preDropTable(Table table) throws MetaException;
public void rollbackDropTable(Table table) throws MetaException;
public void commitDropTable(Table table, boolean deleteData) throws MetaException;The Table object has all the necessary information about the Hive table being processed including its name, database it is part of, Serializer, properties, columns etc. Note that HiveMetaHook does not extend Hook interface.
hive.metastore.filter.hook can be used to filter metadata results. The DefaultMetaStoreFilterHookImpl returns the results as is without modifying. If hive.security.authorization.manager is set to instance of HiveAuthorizerFactory then this value is ignored.
Also, there is hive.metastore.ds.connection.url.hook which allows alternative implementation for retrieving the JDO connection URL. If its value is empty (default case) the value of javax.jdo.option.ConnectionURL is used as the connection URL.
Caveats
- Please note that hook instances are never re-used.
- Hooks are invoked in the normal processing path for Hive. So, avoid doing very costly operations in the Hive pre-hooks and metastore hooks.
